
 Vietnamese
Vietnamese English
EnglishPython Dashによるデータ可視化

Dash とは
DashはMITライセンスで公開されているオープンソースのライブラリです。このライブラリは、Plotly.js、ReactJs上に構築されています。Dashは、カスタム化されるUI(ユーザーインターフェイス)を備えたデータ可視化アプリを構築するのに理想的です。Dashは非常に簡単なので10分未満でUIをソースコードにバインドできます。DashはWebブラウザーにレンダリングされるため、クロスプラットフォーム及びモバイルデバイスで実行できます。
Dash利用のご案内
設定方法
環境:端末でPython 3 がすでにインストールされています。
ターミナルでは、Dashをインストールするために以下のコマンドを実行します。
pip install dash
上記のコマンドの実行により、Dashに加えてpipはチャート描画ライブラリ( Plotly.py)もインストールします。
最後に、次のコマンドを実行することによりPandasライブラリをインストールします。
pip install pandas
Pandasについて
PandasはオープンソースでBSDライセンスで公開されています。Pandasは、Pythonプログラミング言語用に高性能で使いやすいデータ構造とデータ分析ツールを提供します。
Pandasは、DataFrame及びSeriesという2つの主要なデータ構造を提供します。DataFrameは文字、整数、浮動小数点値、カテゴリカルデータといった様々なタイプのデータを列に格納できる2次元のデータ構造です。DataFrameの1行や1列の情報もSeriesに対応します。
列形式でデータを格納するには次の一般的な規則が3つあります。
-
- 長い形式のデータには、観測ごとに1つの行があり、変数ごとに1つの列があります。これは、多変量データ、つまり次元が2より大きいデータの保存および表示に適しています。
-
- ワイドフォームデータには、最初の変数の1つの値ごとに1つの行があり、2番目の変数の値ごとに1つの列があります。これは、2次元データの保存および表示に適しています。

-
- 混合形式のデータは、長い形式と広い形式のデータのハイブリッドです。
Dashのレイアウトについて
Dashアプリはレイアウト及びコールバックという2つの主要部分で構成されています。レイアウトは、アプリがどのように表示されるかを示します。コールバックは、アプリのインタラクティブ性を示します。
「レイアウト」は各コンポーネントを組むツリーです。
DashはDashHTMLコンポーネント、Dashコアコンポーネント、Dashデータテーブル、Dash DAQ、DashBootstrapコンポーネントなどの多種類のコンポーネントを提供します。
この記事では、DashHTMLコンポーネント及びDashコアコンポーネントについて説明します。
DashHTMLコンポーネント
レイアウトのHTMLタグを定義するために用いられるHTMLコンポーネントを提供する関数です。
Dash HTMLコンポーネントの使用を開始するには、次のように.pyファイルにインポートする必要があります。
from dash import html
例:
html_demo.py
import dash from dash import html app = dash.Dash(__name__) app.layout = html.Div(children=[ html.H1(children='Hello Dash'), ]) if __name__ == '__main__': app.run_server(debug=True)
「html.H1(children='Hello Dash')」`はブラウザで「<h1>Hello Dash</h1>」`を生成します。
CHTMLタグと同様に「style」プロパティを使用してhtml_componentのスタイルを変更することもできます。
例:html.H1('Hello Dash', style={'textAlign': 'center', 'color': '#7FDBFF'})
上記のコードは「<h1 style="text-align: center; color: #7FDBFF">Hello Dash</h1>」として表示されます。
DashHTMLコンポーネントとHTML属性の間にはいくつかの重要な相違があります。
- HTMLの「style」というプロパティはセミコロンで区切られた文字列です。Dashでは、dictionary(辞書)を提供する必要があります。
- dictionaryのキー名はキャメルケース形式になります。 したがって「text-align」の代わりに、Dashで「textAlign」になります。
- HTMLの「class」というプロパティは、Dashで「className」になります。
- HTMLタグの子要素は「children」キーワードを使用した引数を介して指定されます。
また、スタイルを直接使用する代わりに、レイアウトにスタイルを定義するためにCSSファイルを利用することもできます。 詳細は下記のURLをご参照ください。
https://dash.plotly.com/external-resources
利用可能なすべてのコンポーネントはHTML Components Galleryで確認できます。
https://dash.plotly.com/dash-html-components
Dashコアコンポーネント
ドロップダウン、チェックボックス、ラジオ、グラフといった高レベルの各コンポーネントのセットを含めるものです。 利用可能なすべてのコンポーネントはDash Core Components Galleryで確認できます。
https://dash.plotly.com/dash-core-components
Dashコアコンポーネントの使用を開始するには、次のように.pyファイルをインポートする必要があります。
from dash import dcc
各コアコンポーネントの中に「Graph」はデータ可視化にとって重要なコンポーネントです。「Graph」は、Plotly.jsというJavaScriptオープンソースグラフ作成ライブラリを使用してブラウザへデータの可視化をレンダリングするものです。Plotly.jsは35種類以上のチャートタイプをサポートし、ベクター品質のSVG及び高パフォーマンスのWebGL形式でチャットをレンダリングさせます。注意すべき点としてはPlotly.jsはブラウザへのレンダリングにのみ使用されています(これがDashで行われる)が、コーディングする時には、Javascriptで直接コーディングせずにPlotly.pyライブラリを使用します(これがDashをインストールする時に提供される)。
Graphコンポーネントの使用方法については、csvデータを折れ線グラフとしてブラウザへレンダリングする例を見てみましょう。
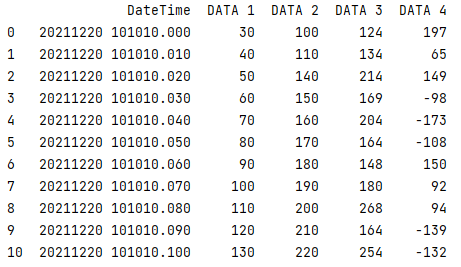
csv/graph_sample.csv
DateTime,DATA 1,DATA 2,DATA 3,DATA 4 20211220 101010.000,30,100,124,197 20211220 101010.010,40,110,134,65 20211220 101010.020,50,140,214,149 20211220 101010.030,60,150,169,-98 20211220 101010.040,70,160,204,-173 20211220 101010.050,80,170,164,-108 20211220 101010.060,90,180,148,150 20211220 101010.070,100,190,180,92 20211220 101010.080,110,200,268,94 20211220 101010.090,120,210,164,-139 20211220 101010.100,130,220,254,-132
まず、csvファイルを読み込むためにpandasを使用する必要があります。
df = pd.read_csv('csv/graph_sample.csv')
変数「df」をコンソールに印刷して、その構造を確認します。
print(df)
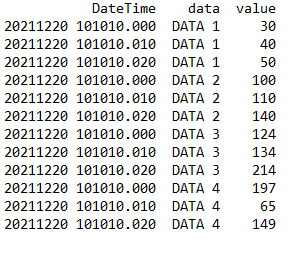
こちらの形式は覚えていますか? そうです。先ほど上記で言及されていたPandasの広い形式のデータです!
次は、DateTime列のデータをstringからdatetimeに変換して、グラフにデータの日時が正しく表示されるようにします。
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y%m%d %H:%M:%S.%f')
そして、plotly expressでline figureを作成します。
line_fig = px.line(df, x='DateTime', y=['DATA 1', 'DATA 2', 'DATA 3', 'DATA 4'])
Graphコンポーネントにfigureを引き渡します。
app.layout = html.Div(children=[
dcc.Graph(id='graph', figure=line_fig)
])
完全なコードは下記のようです。
graph_demo.py
import dash
import pandas as pd
import plotly.express as px
from dash import dcc
from dash import html
app = dash.Dash(__name__)
df = pd.read_csv('csv/graph_sample.csv')
print(df)
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y%m%d %H:%M:%S.%f')
line_fig = px.line(df, x='DateTime', y=['DATA 1', 'DATA 2', 'DATA 3', 'DATA 4'])
app.layout = html.Div(children=[
dcc.Graph(id='graph', figure=line_fig)
])
if __name__ == '__main__':
app.run_server(debug=True)
ターミナルでは次のコマンドを実行します。
python graph_demo.py
最後に、
http://127.0.0.1:8050/ にアクセスして結果を確認します。
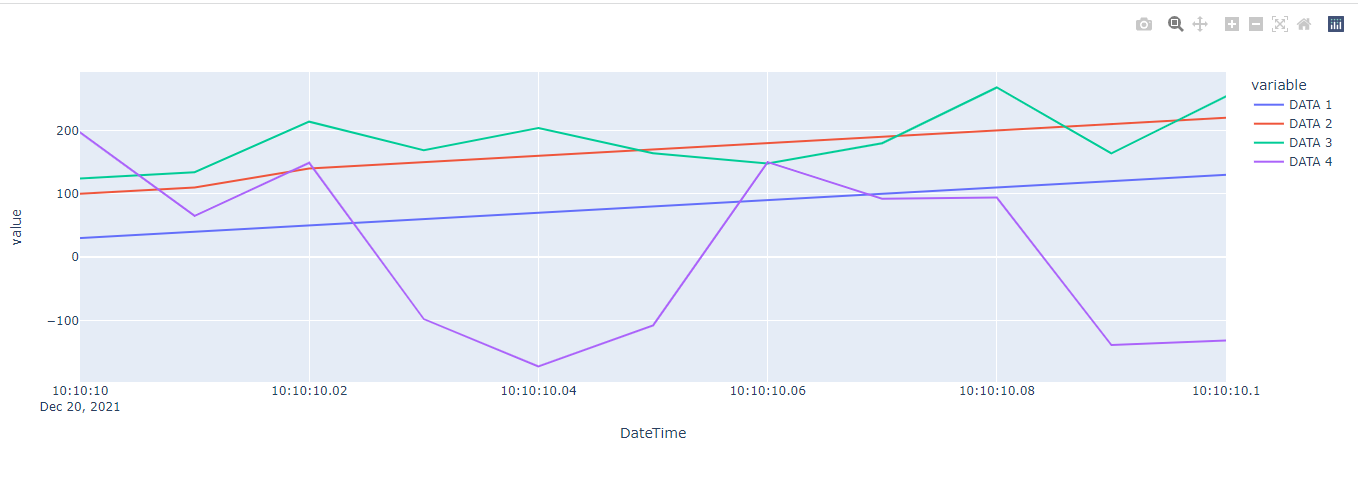
上記の例の中には、
- Pandasライブラリは、入力データを処理するために用いられます(csvを読み取り、DateTime列のデータをstringからdatetimeに変換する)。
- Plotly.pyライブラリにあるPlotly Expressは、出力Graphのグラフタイプ(折れ線図、散布図)、x軸、y軸などを指定する役割を担います。
Dashコールバック
コールバック関数は別のコンポーネント(出力)の一部のプロパティを更新するために、入力コンポーネントのプロパティが変更されるたびにDashによって自動的に呼び出されるものです。
コールバックをより深く理解するには、dcc.DatePickerRangeコンポーネントからの入力を使用して日付でデータをフィルターする例を見てみましょう。
csv/callbacks_sample.csv
DateTime,DATA 1,DATA 2,DATA 3,DATA 4 20211219 101010.010,10,200,178,90 20211219 111010.020,20,150,134,25 20211219 121010.030,5,130,210,11 20211219 131010.040,15,110,100,-97 20211219 141010.050,60,150,143,-17 20211219 151010.060,30,140,132,30 20211219 161010.070,20,180,167,45 20211219 171010.080,16,120,240,123 20211219 181010.090,75,190,153,40 20211219 191010.100,90,250,162,-10 20211220 001010.000,68,142,156,1 20211220 011010.010,40,110,134,65 20211220 021010.020,50,140,214,149 20211220 031010.030,60,150,169,-98 20211220 041010.040,70,160,204,-173 20211220 051010.050,80,170,164,-108 20211220 061010.060,90,180,148,150 20211220 071010.070,100,190,180,92 20211220 081010.080,110,200,268,94 20211220 091010.090,120,210,164,-139 20211220 101010.100,130,220,254,-132 20211221 001010.000,10,90,142,30 20211221 011010.010,30,100,162,55 20211221 021010.020,80,120,180,20 20211221 031010.030,70,110,176,-10 20211221 041010.040,50,130,194,-90 20211221 051010.050,60,140,202,-120 20211221 061010.060,90,150,164,100 20211221 071010.070,120,160,197,132 20211221 081010.080,110,170,186,40 20211221 091010.090,130,210,182,-130 20211221 101010.100,120,230,210,-100
callbacks_demo.py
from datetime import datetime, timedelta
import dash
import pandas as pd
import plotly.express as px
from dash import dcc, Output, Input
from dash import html
app = dash.Dash(__name__)
df = pd.read_csv('csv/callbacks_sample.csv')
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y%m%d %H:%M:%S.%f')
init_start_date = df['DateTime'].min().strftime('%Y-%m-%d')
init_end_date = df['DateTime'].max().strftime('%Y-%m-%d')
app.layout = html.Div(children=[
dcc.DatePickerRange(
id='date-picker-range',
start_date=init_start_date,
end_date=init_end_date,
minimum_nights=0,
display_format='YYYY/MM/DD'
),
dcc.Graph(id='scatter-graph'),
])
@app.callback(
Output('scatter-graph', 'figure'),
Input('date-picker-range', 'start_date'),
Input('date-picker-range', 'end_date')
)
def update_figure(start_date, end_date):
if start_date is not None and end_date is not None:
start_date = datetime.fromisoformat(start_date)
end_date = datetime.fromisoformat(end_date) + timedelta(days=1)
filtered_df = df[(start_date <= df['DateTime']) & (df['DateTime'] <= end_date)]
scatter_fig = px.scatter(filtered_df, x='DateTime', y=['DATA 1', 'DATA 2', 'DATA 3', 'DATA 4'])
return scatter_fig
if __name__ == '__main__':
app.run_server(debug=True)
Dashでは、アプリの入力と出力は単に特定のコンポーネントのプロパティにすぎません。この例では、入力は「date-picker-range」IDを持つコンポーネントの「start_date」及び「end_date」プロパティであり、出力は「scatter-graph」IDを持つコンポーネントの「figure」プロパティになります。
@callbackデコレーターが宣言された関数は、入力プロパティが変更されるたびに自動的に呼び出されます。 Dashは、入力プロパティに新しく入力された値を入力引数としてコールバック関数に提供し(上記の例でupdate_figure関数は「start_date」、「end_date」という2つの引数を持つ)、関数の戻り値を出力コンポーネントのプロパティに更新します。(上記の例でupdate_figure関数はscatter_figを返却)
ターミナルでpython callbacks_demo.pyコマンドを実行し、http://127.0.0.1:8050/にアクセスして結果を確認します。
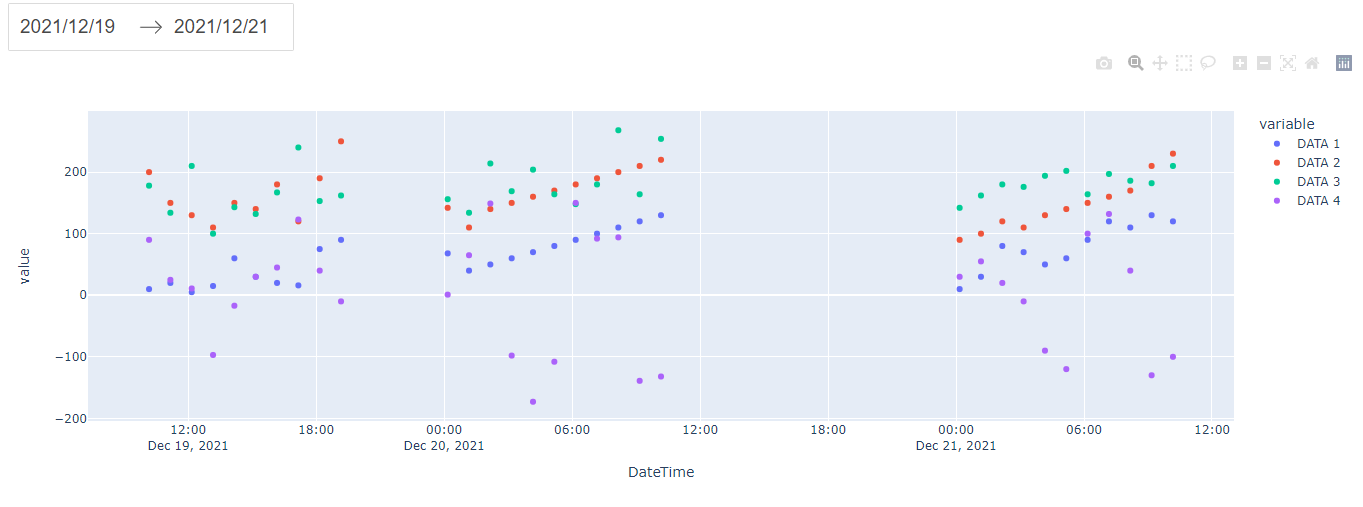
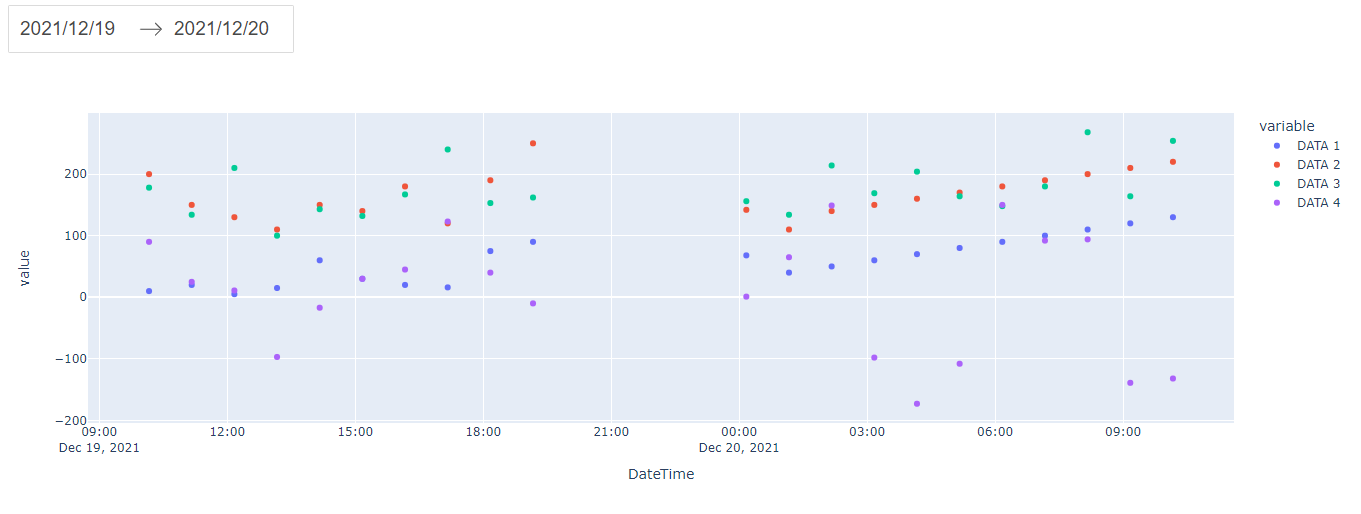
end_dateを変更した後の結果
最適化及び機能追加
この部分ではコールバックのコードを使用してそのコードに最適化して機能を追加します。
データ数nを読み取ります。
現在、入力データの数を4個に固定に設定しています。
scatter_fig = px.scatter(filtered_df, x='DateTime', y=['DATA 1', 'DATA 2', 'DATA 3', 'DATA 4'])
もし入力データが「DATA 1, DATA 2,…, DATA n」どんな量でもあるとすると、上記のコードでは4個のデータしか読み取って表示できません。
データ数nを読み取ってグラフへ表示するには、コードを少し修正する必要があります。
# get first columns name for x-axis x_col_name = df.columns[0] # get list column name except first column for y-axis y_col_name_list = df.columns[1:] filtered_df = df[(start_date <= df[x_col_name]) & (df[x_col_name] <= end_date)] scatter_fig = px.scatter(filtered_df, x=x_col_name, y=y_col_name_list)
CSVのヘッダーからconfigを読み取ります。
CSVのヘッダーを次のように考えます。
DateTime(yyyyMMdd HH:mm:ss.fff),DATA 1(minFilter=20;maxFilter=100),DATA 2(maxFilter=140),DATA 3,DATA 4,DATA 5
上記のヘッダーからconfigを読み取る機能を追加します。
- DateTime列のconfigを読み取って日時の形式を設定します(現在、コードで固定に設定されている)。
- DATA列のmaxFilter、minFilterのconfigを読み取りそのDATA列のminFilterより小さくmaxFilterより大きい値のデータを除外します。
まず、共通関数を含めるutils.pyファイルを追加します。
import re
_format_convertor = (
('yyyy', '%Y'), ('yyy', '%Y'), ('yy', '%y'), ('y', '%y'),
('MMMM', '%B'), ('MMM', '%b'), ('MM', '%m'), ('M', '%m'),
('dddd', '%A'), ('ddd', '%a'), ('dd', '%d'), ('d', '%d'),
('HH', '%H'), ('H', '%H'), ('hh', '%I'), ('h', '%I'),
('mm', '%M'), ('m', '%M'),
('ss', '%S'), ('s', '%S'),
('tt', '%p'), ('t', '%p'),
('fff', '%f'),
('zzz', '%z'), ('zz', '%z'), ('z', '%z'),
)
def convert_py_datetime_format(in_format):
out_format = ''
while in_format:
if in_format[0] == "'":
apos = in_format.find("'", 1)
if apos == -1:
apos = len(in_format)
out_format += in_format[1:apos].replace('%', '%%')
in_format = in_format[apos + 1:]
elif in_format[0] == '\\':
out_format += in_format[1:2].replace('%', '%%')
in_format = in_format[2:]
else:
for intok, outtok in _format_convertor:
if in_format.startswith(intok):
out_format += outtok
in_format = in_format[len(intok):]
break
else:
out_format += in_format[0].replace('%', '%%')
in_format = in_format[1:]
return out_format
def extract_csv_col_config(col_name: str):
try:
found = re.search('\\((.*)\\)', col_name)
col_name = col_name.replace(found.group(0), '')
config_string = found.group(1)
config_list = config_string.split(';')
configs = []
for config in config_list:
key_value_list = config.split('=')
key = key_value_list[0]
value = key_value_list[1] if len(key_value_list) > 1 else None
configs.append((key, value))
except AttributeError:
configs = []
return col_name, configs
上記のコードには、
- convert_py_datetime_format関数は、yyyyMMdd HH:mm:ss.fffの形式をPython形式に変換するために用いられます。
- extract_csv_col_config関数は、configを含む列名を受け取り、config文字列が除外された列名及びその列のconfigを含むarrayを返します。例えば、DATA 1(minFilter=20;maxFilter=100)は、DATA 1とarray [(minFilter, 20), (maxFilter, 100)]を返します。
次に、process_csv_variable関数をapp.pyに追加します。
from datetime import datetime, timedelta
import dash
import numpy as np
import pandas as pd
import plotly.express as px
from dash import dcc, Output, Input
from dash import html
from utils import extract_csv_col_config, convert_py_datetime_format
def process_csv_variable(df_param):
# process x-axis csv variable
old_x_col_name = df_param.columns[0]
new_x_col_name, configs = extract_csv_col_config(old_x_col_name)
datetime_format = configs[0][0]
df_param = df_param.rename(columns={old_x_col_name: new_x_col_name})
df_param[new_x_col_name] = pd.to_datetime(df_param[new_x_col_name],
format=convert_py_datetime_format(datetime_format))
# process y-axis csv variable
y_col_name_list = df_param.columns[1:]
for old_y_col_name in y_col_name_list:
new_y_col_name, configs = extract_csv_col_config(old_y_col_name)
df_param = df_param.rename(columns={old_y_col_name: new_y_col_name})
for config, value in configs:
if config == 'minFilter':
df_param.loc[df_param[new_y_col_name] < int(value), new_y_col_name] = np.nan
elif config == 'maxFilter':
df_param.loc[df_param[new_y_col_name] > int(value), new_y_col_name] = np.nan
return df_param
app = dash.Dash(__name__)
app.layout = html.Div(id='container', children=[
dcc.DatePickerRange(
id='date-picker-range',
minimum_nights=0,
display_format='YYYY/MM/DD'
),
dcc.Graph(id='scatter-graph'),
])
@app.callback(
Output('date-picker-range', 'start_date'),
Output('date-picker-range', 'end_date'),
Input('container', 'id')
)
def update_date_picker(id):
df = pd.read_csv('csv/app_sample.csv')
df = process_csv_variable(df)
x_col_name = df.columns[0]
init_start_date = df[x_col_name].min().strftime('%Y-%m-%d')
init_end_date = df[x_col_name].max().strftime('%Y-%m-%d')
return init_start_date, init_end_date
@app.callback(
Output('scatter-graph', 'figure'),
Input('date-picker-range', 'start_date'),
Input('date-picker-range', 'end_date')
)
def update_figure(start_date, end_date):
df = pd.read_csv('csv/app_sample.csv')
df = process_csv_variable(df)
if start_date is not None and end_date is not None:
start_date = datetime.fromisoformat(start_date)
end_date = datetime.fromisoformat(end_date) + timedelta(days=1)
# get first columns name for x-axis
x_col_name = df.columns[0]
# get list column name except first column for y-axis
y_col_name_list = df.columns[1:]
filtered_df = df[(start_date <= df[x_col_name]) & (df[x_col_name] <= end_date)]
scatter_fig = px.scatter(filtered_df, x=x_col_name, y=y_col_name_list)
return scatter_fig
if __name__ == '__main__':
app.run_server(debug=True)
process_csv_variable関数はDataFrameを受け取り、列名からconfigを読み取りconfigによるデータを処理してからDataFrameを返します。
今、csv/app_sample.csvファイルを追加してテストします。
DateTime(yyyyMMdd HH:mm:ss.fff),DATA 1(minFilter=20;maxFilter=100),DATA 2(maxFilter=140),DATA 3,DATA 4,DATA 5 20211219 101010.010,10,200,178,90,110 20211219 111010.020,20,150,134,25,120 20211219 121010.030,5,130,210,11,90 20211219 131010.040,15,110,100,-97,80 20211219 141010.050,60,150,143,-17,130 20211219 151010.060,30,140,132,30,140 20211219 161010.070,20,180,167,45,150 20211219 171010.080,16,120,240,123,160 20211219 181010.090,75,190,153,40,150 20211219 191010.100,90,250,162,-10,170 20211220 001010.000,68,142,156,1,180 20211220 011010.010,40,110,134,65,130 20211220 021010.020,50,140,214,149,190 20211220 031010.030,60,150,169,-98,200 20211220 041010.040,70,160,204,-173,190 20211220 051010.050,80,170,164,-108,180 20211220 061010.060,90,180,148,150,170 20211220 071010.070,100,190,180,92,150 20211220 081010.080,110,200,268,94,160 20211220 091010.090,120,210,164,-139,140 20211220 101010.100,130,220,254,-132,130 20211221 001010.000,10,90,142,30,150 20211221 011010.010,30,100,162,55,160 20211221 021010.020,80,120,180,20,170 20211221 031010.030,70,110,176,-10,110 20211221 041010.040,50,130,194,-90,90 20211221 051010.050,60,140,202,-120,80 20211221 061010.060,90,150,164,100,70 20211221 071010.070,120,160,197,132,60 20211221 081010.080,110,170,186,40,50 20211221 091010.090,130,210,182,-130,40 20211221 101010.100,120,230,210,-100,30
ターミナルではpython app.pyコマンドを実行し、http://127.0.0.1:8050/にアクセスして結果を確認します。
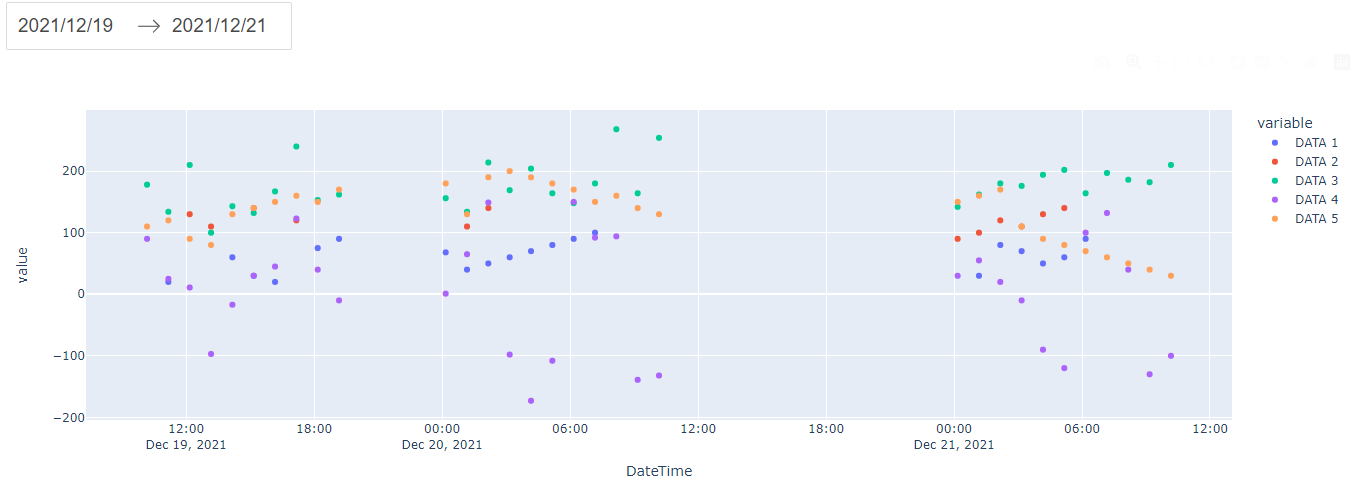
結果を確認しやすくするために、他のデータを非表示にしDATA1のみを表示します。
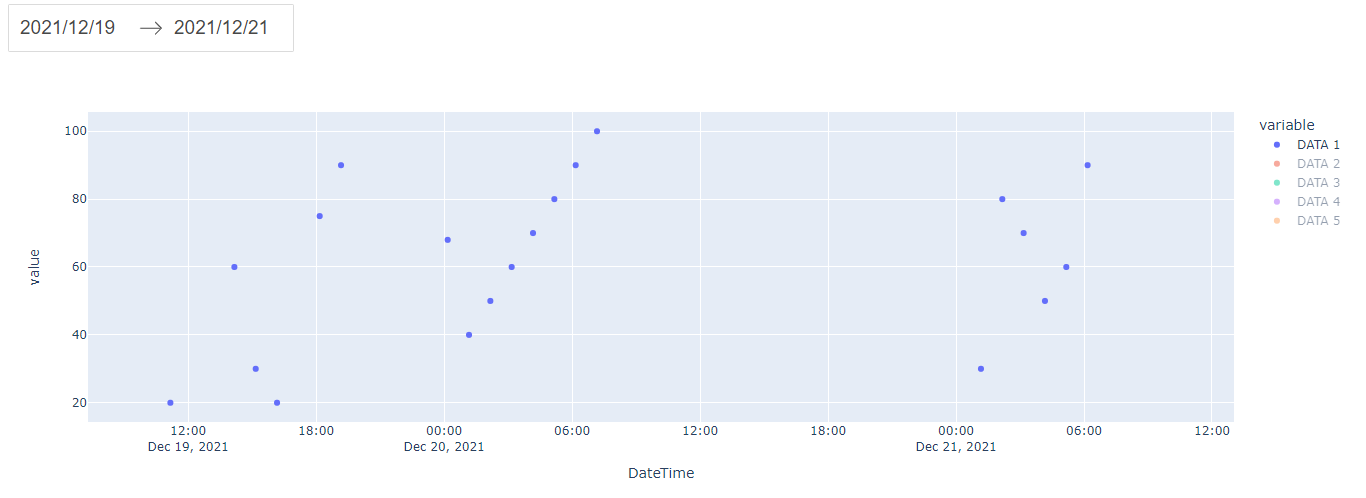
20より小さい値及び100より大きい値のデータが除外されていることがわかります。
ソースコード
https://gitlab.com/bwv-hp/python-dash-sample